A critical look at the anyNA() function in R
The anyNA() function was introduced in GNU R in version 3.1.0 using what has become a fairly common approach to solving performance issues in GNU R. In this article I want to take a critical look at this function: what problem is it trying to address and how? In particular, I will argue that the solution is less than ideal and that the design of Renjin's R interpreter provides a much more flexible approach to performance improvement.
When we presented our work on Renjin during the R Summit in Copenhagen I briefly touched on my dismay at the introduction of the anyNA() function. But before I tell you about what is wrong with this function I will explain why it was introduced in the first place.
History of GNU R's anyNA() function
Back in 2006, Henrik Bengtsson porposed the has.na() function on the r-devel mailing list and asked about it again in August 2007. Why? Because he correctly observed that any(is.na(x)) is (unnecessarily) expensive and thus inefficient for a large vector x. Internally, GNU R will first create a logical vector to store the result of is.na(x) and then loop over the full result to determine if any elements are NA.
About 5.5 years later Tim Hesterberg, who participated in the discussion about anyNA() in 2007, filed a request to enhance GNU R with the addition of the anyNA() function and provided a C implementation which was incorporated into GNU R in version 3.1.0. The C implementation is very efficient because it doesn't assign the intermediate result and it stops looking once it finds the first NA element. If we were to program this solution in R, it could look like the following implementation[^1]:
anyNA <- function(x) {
i <- 1
repeat {
if (is.na(x[i])) return(TRUE)
i <- i + 1
if (i > length(x)) return(FALSE)
}
}
Of course, the C implementation will be compiled to machine code so it will be much faster than the R implementation.
So far so good.
My critique on anyNA()
So what is wrong with this approach? This is what I think (in no particular order):
- It only solves one particular problem, but leaves many similar problems unresolved. All three examples below will not benefit from the optimization in
anyNA()ifxis a very large vector. So instead of solving the issue under the hood, namely in the interpreter itself, a workaround is bolted onto the side of it.
y <- is.na(x); any(y)
any(is.na(x) | is.na(y))
all(!is.na(x))
- The introduction of a specialized function increases the number of functions in R's base package and thus clutters the API making it harder for newcomers to grasp which functions they should use. A better idea would be to collect these kinds of functions in a separate package and to make this a recommended package.
- There is another function which could have served as an example of what
anyNA()should return, namelyanyDuplicated(). The latter function essentially is a replacement forany(duplicated(x))but returns the index of the first duplicate, notTRUEorFALSE. Aside from the question which output makes more sense, it would have been more consistent to letanyNA()also return the index of the firstNAinx. - to make matters worse, the bugzilla issue shows that a discussion about the name of the function, came after it was released in R. It could have been named
anyMissing()orhasNA()depending on who was the committer and his or her mood on the day of the commit. This tells me that R's API (i.e. the set of functions available to the user) is not carefully curated by R's developers.
Other examples
If you think anyNA() is an isolated case, then you are wrong. Another example is paste0(). The lack of creativity when naming this function should be obvious. Most people will use paste0() instead of paste() but not because it is faster in concatenating large vectors. They use it because they prefer the default separator, sep = "" instead of sep = " " in the case of paste(), and thus paste0() saves them from typing a few extra characters.
Or take lengths(x) which is a more efficient version of sapply(x, length) for a large list x. This function was committed to R's code base by Michael Lawrence on February 6, 2015 seemingly without any prior discussion on whether this is a useful addition to R's already extensive list of functions in the base package. A discussion may have taken place off-line, but all we have is a mention in the project's NEWS file.
Renjin's implementation of the anyNA() function
It just so happens that we had already solved the inefficiency of any(is.na(x)) in Renjin when the anyNA() function was introduced to R. In fact, this solution was made very easy by the high level of abstraction in the data types in Renjin's interpreter.
The following figure is taken from the section Overview of Renjin’s type system in Renjin's documentation.
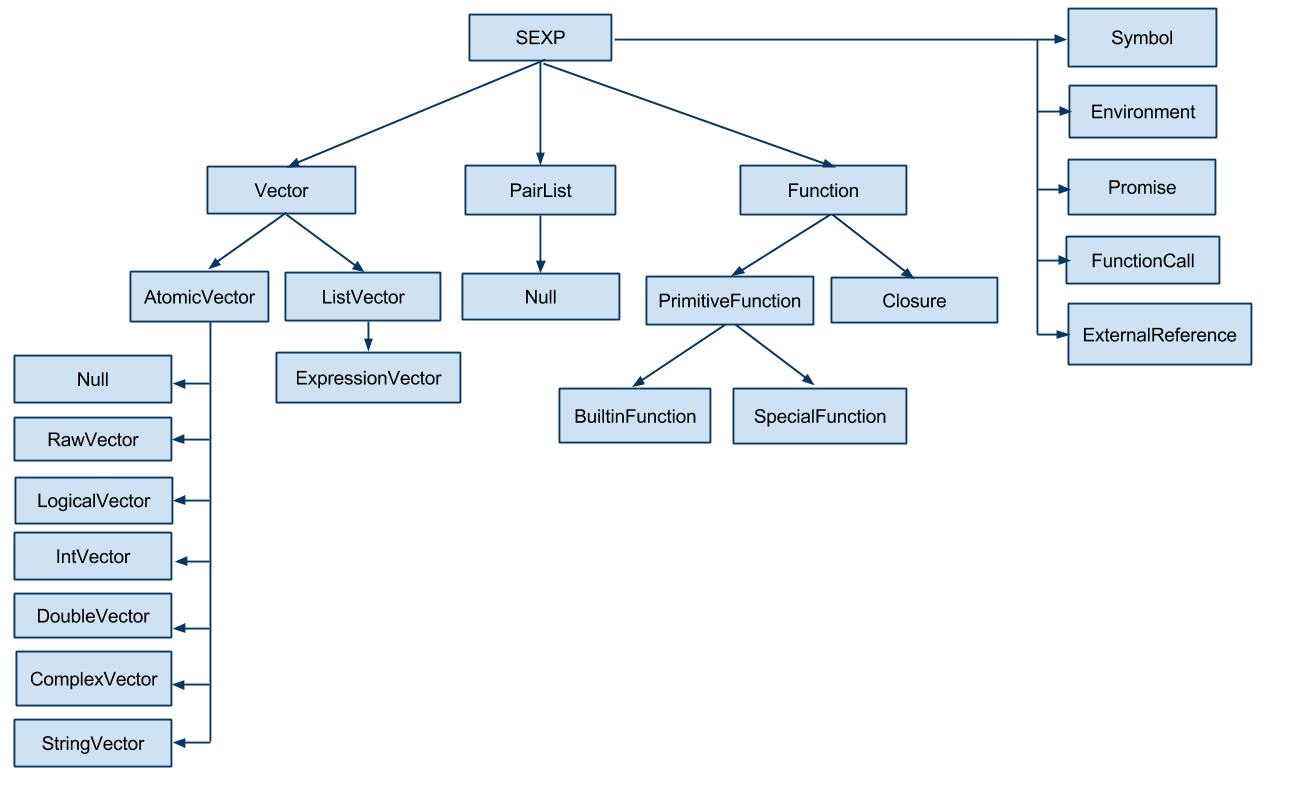
At the top you see R's well-known SEXP object type, followed by the Vector and AtomicVector Java interfaces. The latter includes classes for the six atomic vector types in the R language, one of which is the LogicalVector type. When the is.na(x) function is called in Renjin and the vector x has more than 100 elements, the interpreter will not allocate any memory. Instead it will return a special type of the LogicalVector class which is appropriately named IsNaVector. So Renjin knows that this vector is a result of calling is.na() on the (known) vector x but it will not materialize this vector until it really needs to. In a sense, the IsNaVector class returns a 'view' of is.na(x). Calling the any() function will then loop over the elements of the view and return TRUE as soon as it finds an element equal to NA. Like in GNU R's implementation of anyNA() no vectors, aside from x itself[^2], are materialized in the process.
With this issue already solved in Renjin, all we had to do to implement anyNA() was to provide a simple stub which we put in the appropriately named renjinStubs.R file.
Conclusion
I have argued that the addition of the anyNA() function to GNU R's base package solves only a narrow part of the problem and that the naming and behavior of anyNA() (and similar functions) creates a bloated and inconsistent API. My advice to people is not to use these functions unless absolutely necessary: it will make your code more concise and elegant.
We have designed Renjin's R interpreter in such a way that we can implement broader improvements to the memory usage and execution speed of R programs without adding more functions. We believe that users should not have to rewrite their R programs to achieve faster code execution or to reduce memory requirements.
Convinced? Curious? Download Renjin and give it a try!
[^1]: note that anyNA() nowadays does a little more than just replace any(is.na()). It is a generic function with a recursive=FALSE argument which was added in R version 3.2.0.
[^2]: there are some examples in which even the vector x is not materialized. For example if x <- seq(10^6) then Renjin will use a special class called DoubleSequence to efficiently represent this long sequence of numbers in memory.
Read more at Renjin's blog or subscribe to the blog's RSS feed.